Have you ever heard about “Clean Architecture” ? This is still a very popular topic for discussion and experiments. Moreover attention to this topic promises to increase dramatically, because of Uncle Bob’s upcoming book. This concept was implemented in a lot of programming languages. I got interested in this topic a few years ago after I had experienced problems with scaling one of my project. I started to study it greater details and found a lot of great concepts that make a software architecture cleaner. After I had explored Clean Architecture a little bit deeper I found it really useful and worth to use in my projects, however there are some points I don’t agree with, or maybe I haven’t understood them properly.
I wanted to write this series of articles much earlier (few years ago), but until now I didn’t have a chance and time. Let me hasten to say, that this is not the only right way to follow in your project, this article is just the interpretation of my understanding of Clean Architecture and nothing more, if you have another point of view, this is really great and I would be grateful to discuss it with you. Furthermore this post series is not a How-To guide, it’s intention is to change something in the way you think about software architecture.
In this post series I want to share my experience dealing with the concept of Clean Architecture with the Android background. This topic is still highly discussed, but was proposed quite long time ago.
Introduction
I called this post series Android Clean Architecture at first, but changed the name later as far as most techniques and ideas described here can be applied for different programming languages or frameworks. The main idea is to explain the most important concepts. I regret to inform you that this post series won’t contain a lot of code and real examples. This series is more theoretical and intended to describe main ideas and practices. I am planning to create another post series that will be directly focused on a real project. I hope I will add a link here soon.
A little bit of Clean Architecture history
Let’s start our journey from history of the term Clean Architecture. Everything has begun from an article written by a well-known software engineer Robert Cecil Martin AKA Uncle Bob. I hope you know this guy, as far as Uncle Bob has written a number of great books on Agile Practices, Code Style (Clean Code), Object Oriented Design and other topics. There are a lot of addressed contentious issues, but nevertheless his books are worth reading.
An article named The Clean Architecture was published on the August 13, 2012. Yeah, five years ago. This article is relatively short, but it cut a wide swath in the programming community a few years later. Here is a concise summary of the article.
- Independence from Frameworks. An architecture should not depend on frameworks, you should be able to swap a framework with the least effort.
- Independence from Details (UI, DB, transport protocol). A software system’s core logic should not be affected by changes in UI, Databases, Frameworks, Libraries, etc.
- The Dependency Rule. An inner layer should not know anything about upper/outer layers. As a result dependencies can only point inwards.
- Entities and Use Cases. Entities and use cases are the core of an application. These layers are the most important when we are talking about an architecture. And these layers should not be affected by changes in “detail layers”.
- The necessity of using adapters and converters. Adapters and converters are used to convert models when they are propagating between layers to make them convenient to work with on a specific layer and do not spread extra dependencies to other layers.
- The Dependency Inversion Principle This principle states that “High-level modules should not depend on low-level modules. Both should depend on abstractions” and “Abstractions should not depend on details. Details should depend on abstractions”. This is very important principle and doesn’t specifically related to The Clean Architecture term, it is just one of best practices for software creating in general.
- Passing data between boundaries. You should always pay attention to objects being passed between layers. An object being passed should be isolated, simple or even just a plain data type without hidden dependencies. You can encounter problems when you are using ORM (Object Relational Mapping) libraries and passing ORM objects outside the boundaries. For example NSManagedObject.

A few years later after the article was published, this idea become a hot topic for discussions and a lot of new articles and blog posts were published. One of the most valuable (for me personally) is a blog post written by Fernando Cejas called Architecting Android…The clean way?. The idea of this article was to apply the Clean Architecture practices described by Uncle Bob to Android Development. This article caused a lot of github issues containing architectural questions regarding this approach, there are a lot of valuable information can be found there, I suggest you to explore some issues. I am going to dedicate a separate post series to this repository since there are lot of question to discuss in this project.
Uncle Bob didn’t mess around all this time an wrote some good articles. Here is one of them A Little Architecture it is written in the form of interview, I advise you to read it as well. Finally, Uncle Bob is currently working on a book called Clean Architecture: A Craftsman’s Guide to Software Structure and Design (unexpectedly ?). The book promises to be really valuable and will probably shed light on the most moot points.
There are a number of other great articles about Android Clean Architecture, you can google to find them. What about other programming languages and SDKs ? Almost every programming language has an example project written considering the Clean Architecture principles. In iOS world there is one more great example – the VIPER architecture. It came as a replacement for MVC (pronounce it properly Massive-View-Controller). I suggest to read a great book The Book of VIPER about this approach on Github.
Why should I care about an architecture ?
You might have asked yourself this question or you heard it from you colleges. But in order to find out an answer for the question, I offer you to answer the following questions instead.
- Why do we have such a great number of programming languages and frameworks?
- Who really needs high level programming languages?
- Do machines “prefer” high level languages over low level languages like assembly?
- Have you ever fear to change even small parts in your project ?
- How much time did you spend to understand codebase of a project after a certain amount of time ?
- How much time do you need to explain the architecture of a project to a completely new person ?
The idea I want to convey here is the following. We, as developers, only need all these high level languages, frameworks, syntactic sugar structures, one-line solutions, first of all for our convenience and ease of remembering language structures. Machines have nothing to do with pretty human readable code. So why these tools very often are not used properly and we have a lot of “spaghetti code” and “Big balls of mud” ?

Sometime we really need to meet requirements and hit the deadlines. But even in this case we should keep our project at least well structured, readable and extendable. Here are some cases when time spent for developing an architecture, exploring a domain, separating a domain into multiple contexts or layers doesn’t worth the effort.
- No pronounced architecture or domain. When software is very simple, like a simple CRUD application, that doesn’t have use cases other than CRUD (Create, Read, Update, Delete). Or a number of use cases is really small.
- Scripts or command sequences. A simple script, a sequence of bash commands, etc.
- Source code/application size restrictions. Adhering to the principles like Separation of Concerns, DDD, SOLID, abstraction, etc., brings some overhead as a result your codebase size can increase dramatically. This limitation is particularly relevant for embedded applications. Usually most embedded applications are written considering performance and robustness in the first place.
- The first time. If you are only trying to understand the idea of The Clean Architecture and you have a project with strict time limitations imposed, grasping “clean principles” may take a tremendous amount of time or transform your project into something even worse than it was before.
However, in most other cases understanding and applying architectural principles, best practices not only will help you to create better applications but will make you more valuable as a developer. Exploring different existing approaches will help to think in the context of software and more importantly to adapt an architecture to specific requirements, as a result you will be able to make critical software architecture decisions.
I am not going to list all benefits of using Clean Architecture and related principles like testability, scalability, I hope they are obvious. A good software architecture like a solid foundation, not only makes an application extensible, testable, but reduces the risks of the overall system fault and even developers’ mistakes in small modules without crashing a whole system.
Architecture Evolution
To understand why the Clean Architecture is better (or worse) than other existing architectures, we need to look at the way how different software architectures evolved. We will discuss several most popular architecture groups.
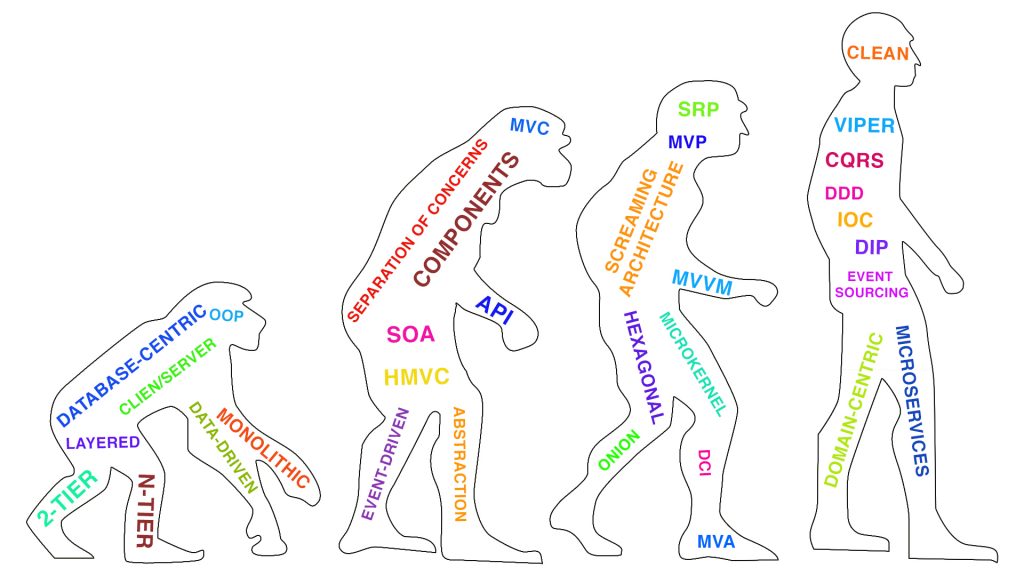
I would divide all known architectures into two groups :
- Database-centric architectures
- Domain-centric architectures
Let’s see examples of each group. But the last thing I want to address is the term “Database centric”. Do not be confused with the term “Data centric” or it is better to say “Data driven”. The former means that everything resolves around a database, but the latter implies that all use cases and interactions are driven by data(information). I think you’d have to agree, that every single software application without exception works with some sort of information. That’s why we (developers) are working in the IT (Information Technology) field.
Database-centric architectures

The first group we will cover is Database-centric architectures. Architectures of this type were the first software architectures ever.
Database centric principles are still widely used by developers while building applications and systems. We have a lot of legacy systems still running in production, that are really hard to extend and maintain. However, more importantly is the fact that architectures like 3-Layered, N-Tier are still been taught in universities, moreover in the worst case they are taught as the only possible architectures to use while building a software system.
Tiers vs layers
To be on the same wavelength, we need to understand the difference between a layer and a tier in the context of software development.
Layers refer to a logical separation of concerns. You are organize and split your code into several layers in accordance with responsibilities, define communication protocols between layers. As a result you have separate components that could be swapped with another implementation without affecting a whole system. In case of 3-Layered architecture you will probably have the Presentation, the Business and the Data layers. You could have all these layers running on a single machine, albeit, for instance, the Presentation layer may occupy several physical machines, one is running a website, another an API.
A tier, on the other hand, is more about physical organization of you code, module and components. A tier is a deployment unit. However, nowadays it doesn’t mean that an N-Tier application can only run on N separate physical servers. Thanks to virtualization technologies is is possible to run an N-Tier application on a single machine. You are probably aware of such technologies like Docker, KVM, LXC…
Personally, I have been taught to use the 3-Layered architecture, since it is time-proven, robust and scalable. I remember the times when we started a new project and the first thing we put in our todo plan was the Relation Modeling for a specific domain. As a result we began from creating tables and relations… And continued to create triggers, stored procedures implementing business logic of a problem domain directly in a DBMS.
Anything should be judged by comparison, therefore the 3-Layer Architecture is not the worst one. This was an attempt to separate concerns to gain flexibility and extensibility of a software system. Ideally layers in the 3-Layer architecture should have the following responsibilities:
- Presentation Layer: The main duty of this layer is delivering an application functionality through a UI (User Interface). It could be implemented in the form of a Web Page, using a native windowing system or even by building an API. This layer should be kind of dumb comparing to other layers.
- Business Layer: This layer is the place where all business logic and application logic should happen. In case of the 3-Layer architecture it should be independent from the Presentation layer, however it is still has an explicit dependency to the Data layer
- Data Layer: The bottommost layer that serves requests coming from the Business layer usually translating them into queries to the underlaying data storage. At best it should be an abstract data repository interface, free of any business rules and application logic.
A great attention is paid to the database. The Data layer is considered as the most valuable part of an application architecture. Therefore, very often The Data Layer and The Business layer are mixed together so tightly that it is much easier to rewrite the whole application instead of diving into existing codebase. Here is an example of such code, it is really terrible.
1 2 3 4 5 6 7 8 9 | def get_user_balance(user_id)
connection = Mysql.new 'localhost', 'username', 'password', 'bank'
query_history = connection.prepare "INSERT INTO history ( user_id, type) VALUES (? ,?)"
query_history.execute user_id, 'check_balance'
# Get balance
query_balance = connection.prepare "SELECT user_id, sum(amount) AS balance FROM transactions GROUP BY user_id WHERE user_id=?"
result_balance = query_balance.execute user_id
result_balance['balance']
end
|
I hope you see how many problem does this code have. It doesn’t even conform to the 3-Layer Architecture. In this instance we don’t have the Data Access Layer at all and we are accessing the data directly. Despite all these problems, dependencies are still pointing from the Business Layer to the Data Layer.
One essential thing in any architecture are the directions of dependencies, how do each layer depends on another. Let me explain what do these arrows mean in real code. The Presentation layer imports classes or modules from the Business layer, in it’s turn the Business layer depends on the Data layer. In a programming language dependencies are mostly represented via using, import, include, require statements.
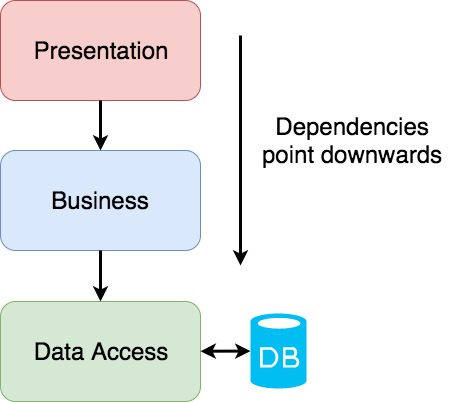
In the worst case, the Presentation layer transitively or explicitly depends on the Data layer. For example, you may encounter this problem when you are dealing with ORM, reusing the same model class across multiple layers.
Let’s assume we have not only three layers, but some more layers containing business rules, infrastructure services, etc. Unfortunately they will also point to the Data layer, this could be illustrated in the following way.
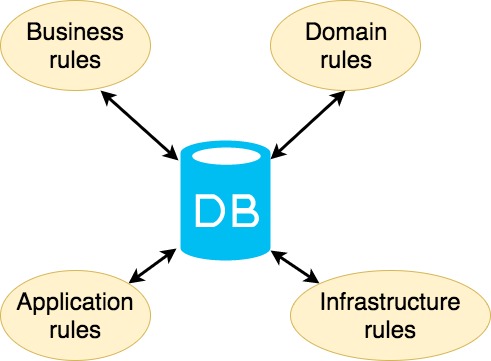
Moreover, as I have already mentioned, the boundaries between the Business layer and the Database layer are really thin and brittle, making it possible for business logic slowly leak into the database.
Domain-centric architectures

The next evolutionary step in software architecting was changing the values of a classical software architecture (like 3-Layer). The focus of developers was moved from the Database layer to the Business layer and solving business problems in general. Why ? To answer this questions follow this question-answer chain.
Changing priorities
- Q: Why do developers have their work ?
- A: Because, software executed by hardware automates routine tasks.
- Q: Who is usually the most interested in automating processes and tasks ?
- A: Business.
- Q: What are the main goals ?
- A: To contribute to a business growth and achieve its objectives, be competitive and therefore make money.
- Q: How does software conduce to this ?
- A: It solves business problems of a specific domain, automates business flows.
Could you find any framework, DBMS, tool being mentioned in this questionnaire ? Don’t understand me wrong, they are really important and you as a developer need to have a bunch of tools that you are comfortable to use in order to complete a project. But, they are just details, helpers, delivery mechanisms that only help to accomplish stated tasks.
Business is constantly changing. It requires rapid responses to new challenges and be able to remain competitive in your area.
You may wonder why I am talking about this and how do you relate to all these business processes. You need to be productive as a developer to satisfy all new requirements as quickly as possible, this will make you an undoubtedly valuable expert.
Consider the following case. You are a mobile developer and currently working on an Android app. Your boss has just ran into your room yelling, that we need an iOS app as soon as possible, since our competitors has just released their iOS client application.

Now everything is up to you or your colleges, how quick could you respond to new changes. If you are going to develop the iOS app as well, then the main question how much time do you need to implement all business and domain cases in the iOS app. In case your colleague will develop the iOS app, they should spend some time understanding you code and overall architecture.
As usual business logic is spread over all layers of an application, of course if there are any layers :). What is more important you may not even understand that your UI is full of business rules, but they are not so obvious. Therefore to replicate all business rules, already implemented in some app, you will need to put all pieces together, assembling each as a puzzle piece to reveal the complete domain core, stripped out from frameworks, databases and other details. So the question maybe it would be better not to burden all layers with business logic, but keep all domain rules in one place, as a result save your time and make you more productive ?
The more business rules are abstracted and decoupled from details, the easier it will be to create a quite different application from the technical point of view, but with the same business rules.
Converting a database-centric architecture into a domain-centric architecture
To understand difference between two groups of architectures, let me show how easily you can convert a database-centric architecture into a domain-centric one.
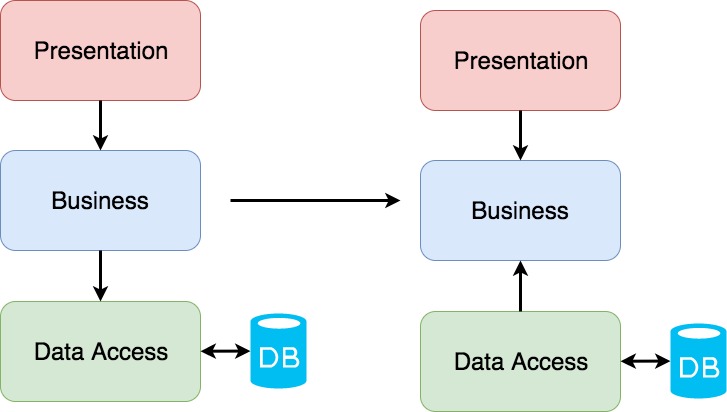
Of course this is not always as easy as shown above. But I am just trying to make a point of the main idea here. It could be much more complicated, since architectures are mostly not used in their canonical form, but modified to meet specific requirements. The main idea that the Domain layer should not have any dependencies on details pointing outward. Just to make a bit clearer, here are two code snippets, representing how two different approaches may look in code.
Database-centric approach
1 2 3 4 5 6 7 8 9 10 | package ua.com.crosp.testapp.domain;
import ua.com.crosp.testapp.datalayer.PostsRepository;
public class GetRecentPostsUseCase implements GetRecentPostsUseCaseContract {
private PostsRepository mPostsRepository;
public Single<Post.List> execute(Params params) {
// Execute
}
}
|
Domain-centric approach
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package ua.com.crosp.testapp.domain;
import ua.com.crosp.testapp.domain.PostsRepositoryContract;
public class GetRecentPostsUseCase implements GetRecentPostsUseCaseContract {
private PostsRepositoryContract mPostsRepository;
@Inject
public GetRecentPostsUseCase(PostsRepositoryContract repository) {
mPostsRepository = settingsRepository;
}
public Single<Post.List> execute(Params params) {
// Execute
}
}
|
Please note the import statements, in the first case we are including the class from the Data layer, of course in better case it should be an interface, however that doesn’t make any difference, as we have dependency to the Data Layer. In the event of the Domain-Centric approach we don’t have any dependencies to other layers, instead the Domain layer dictates the rules of the game.
So keeping all these problems and objectives in mind some clever guys started to adapt and refactor existing architectures putting the domain problems on the first place.
Domain Driven Design
One of the first architects who defined domain driven design principles was Eric Evans. He wrote a book about concepts of designing software that is driven by domain problems rather than details. This is not an architecture, but rather a set of advice and principles to consider while creating a system that deals with complex domains.
I won’t cover these principles in details, due to a great number of really valuable articles and books on this matter, I want just to highlight the most important points of these principles.
- Bounded contexts. A whole application domain layer is split into smaller ones. Each subcontext has some models, that make sense in this context, as well as it has it boundaries. Such subcontext is called bounded context. Dividing the application domain into bounded contexts makes an application even more maintainable, loosely coupled and reusable. For example, you may have multiple Customer models across you domain, but each of them belongs to a specific bounded context. Why ? Have you ever had a model class with more than 10 properties, due to the same name used for different concerns in the application. Most of these properties are not used regularly and exist only because you, guided by the same name, combined two completely different entities, from the domain perspective, into single one.
- Ubiquitous Language It is very important to have understand all terms in a specific business domain, because there a lot of words that have different meanings depending on the context they are used in (homonyms). This language should be based on the business domain. The Ubiquitous language is like a link between you (developers) and domain experts/stakeholders. It helps to eliminate contradictions during the project lifecycle.
- Entities and Value Objects Entities are business models that have their lifecycle, identifier and a business value. Usually a domain expert operates in terms of entities. Entities have their state and are able to change, therefore they are mutable. Furthermore, Entities should be uniquely identifiable, hence they are compared by a unique identifier, for example there may be two orders with the same products, but from the business point of view they are completely different. Value objects are immutable objects usually used as attributes. They should be immutable and are tested for equality by their properties. Value objects may have some constraints, like not all strings that have the at sign (@) are valid email addresses. For instance, we can treat a date, a price, a point, a weight as a Value Object. A Post, an Order, a Customer could be an example of an Entity.
- Aggreagtes and Aggregate roots Typically we have multiple objects that form a single unit that is treated as a whole, and in the context of DDD it is called an Aggregate. For instance, it could be a system process (i.e. a Linux process). A process usually have associated threads, file descriptors, environmental variables, memory regions. But on their own without the process context their make little sense. An Aggregate Root is an Entity that is visible for outer world and is used for all communications with an aggregate. In the previous example a thread can be accessed usually only in the context of the process, therefore the process in this case is the Aggregate Root.
All in all the main idea is to represent software architecture as close as possible to how the business sees the problem domain. This helps to stay on the same page with domain experts, but what is more important to keep our software system maintainable and ready for domain rules changes without spending months rewriting 50% of a project.
The Hexagonal architecture
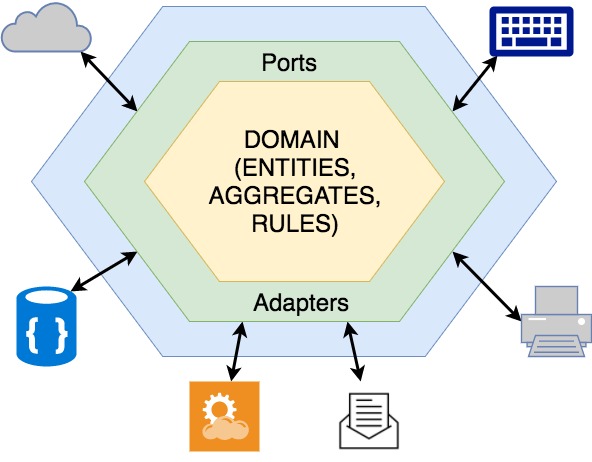
One of the first architectures with the domain layer placed in the core, was the Hexagonal Architecture. It consolidated some important principles. The idea of this architecture is really easy to understand. The essence is that the Domain layer should be segregated from the outer world (details, frameworks, UI). Therefore there are two main regions in this architecture : the Outside region and the Inside region.
- Inside and Outside There are two main areas defined in this architecture. The Inside region contains all business logic, domain rules, domain objects, aggregates and contexts. By way of contrast the Outer region is all details, building blocks, tools, frameworks that provide necessary functionality for the Inside region. Two regions are wired together via Adapters and Ports
- Ports and Adapters In order to prevent the Application core from details and dependencies Ports and Adapters used like mediators between two worlds. A mediator is like a fuse installed in almost any device protecting it from overcurrent. The same principle applied here to prevent the business logic leak outside, keeping the application core solid. An Adapter in this architecture is used like a communication bridge between services required by the Domain core. A Port is like an API, only specific application functionality and features are exposed (Principle of Least Privilege and Interface Segregation Principle).
- Dependencies point inside The main idea of a Domain Centric architecture is followed here as well. All details are just satisfying the core of application with required features usually defined in the form of interfaces in the Domain layer.
I’m referring to the innermost layer as the Domain Layer, however it may have other names, like the Application layer, even more sometimes this architecture may be divided into more than two layers, however the main essence stays the same. Two distinct regions is used to separate domain rules from details and frameworks, providing only necessary interfaces for communicating with the Application core.

Moreover, always remember to design you ports and adapters in the right way, at least ensure they are usable.
The Onion architecture
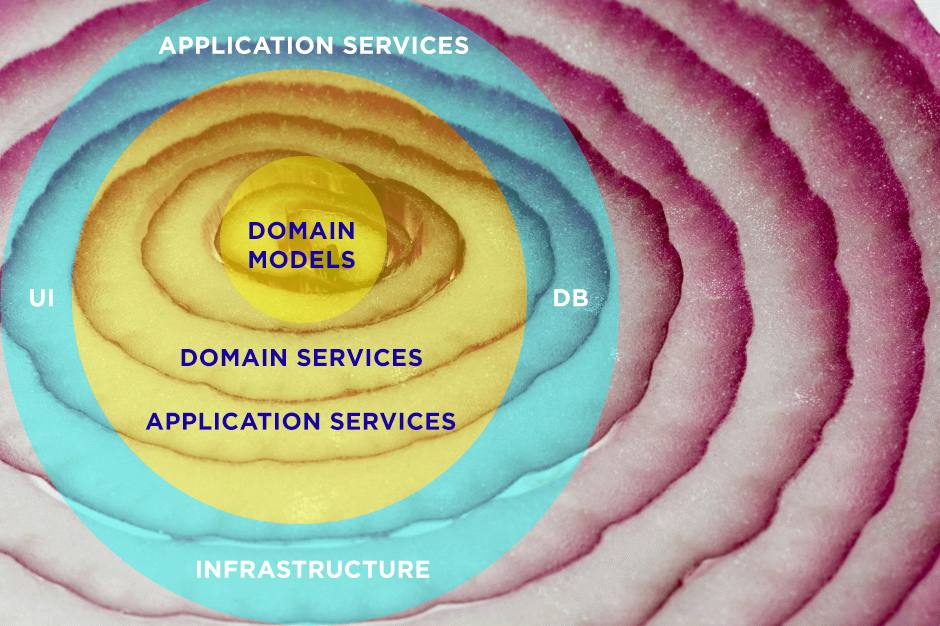
The next and the last architecture I want to cover in this article is the Onion Architecture. You probably already guessed where does this name come from. This architecture was created inspired by the DDD principles and Dependency Inversion principle. You may have noticed that each next architecture we review has more layers and is more detailed itself, but the main ideas stay the same.
Additional layers were introduced to provide a better Separation of Concerns between parts of a system. The Application layer is one more mediator between the outer world and the Domain core. Usually it contains Use Cases that are used throughout an application. Usually a Use Case may act like an assembly unit, that collects all required input data, directs it to the Domain Services and returns the result back to the calling party. Multiple use cases can be combined and reused according application rules. We will see later how this layer could be designed and implemented.
How do the DDD principles relate to domain-centric architectures ?
You may have this question in mind. Domain Driven Design is just a set of principles for modeling the core layer of an application. It is more about strategies, patterns and practices for designing the most important layer of any domain-centric architecture – the Domain/Business Layer. All mentioned architectures on the other hand, just explain how should an overall system architecture look like, but don’t pay much attention to implementation details. Consequently, if you decided to use a domain-centric architecture as a foundation for your system. Then, it could be a good choice to find an architecture that fits your requirements the most and then turn to the design of the Domain layer taking into account the DDD guidelines.
What architecture to use ?

Personally, I strongly suggest you NOT to use any of these and further explained architectures in their pure forms. To be a good architect you should make important decisions yourself instead of following how-to guides. Every project is unique and requires a distinct approach. I think, this is great to be aware of different architectures and approaches, this will help you to find weak and strong points of them and as a result define an architecture for a specific project. Of course, do not forget to follow best practices like Separation of Concerns, Inversion of Control and keep your codebase clean and maintainable.
Furthermore, mostly all these architectures are defined without providing a concrete source code, that is a good point, I think. An architecture is an abstract thing itself, it is just a set of concepts, rules, practices. Therefore the main idea of all these posts and articles (including mine) just to make you grasp important concepts, allowing you to make conscious decisions regarding the future of a software system.
Conclusion
The intention of this article is to show two different approaches for designing an architecture, maybe to change the way you think about the software architecture. There are a lot of domain-centric architectures, but they are roughly the same, all of them stick to the same philosophy. Furthermore, both domain-centric and data-centric architectures may seem similar from the first sight, and that is partially true, since they may have the same layers. The main difference is dependency arrows, the rules defined by these arrows referred as a single term – the Dependency Rule. In the next chapter we are going to discuss one more domain-centric architecture – the Clean Architecture itself.
Hi, my name is Molochko Alexander, I am Interested in different areas of software development, curious about learning and discussing architectural and software patterns, examining internals and understanding how everything works under the hood.
Recent posts
- Mar 1, 2020 Implementing Laravel custom Auth Guard and Provider
- Feb 16, 2019 Hacking Java Applications with Byte Buddy and Decompilers
- Jan 5, 2019 Page Specific Dynamic Angular Components using Child Routes
- Oct 13, 2018 Understanding Dagger 2 Scopes Under The Hood
- Jul 21, 2018 Understanding and using Xdebug with PHPStorm and Magento remotely
Popular posts
- 143595 Views How to Install The Latest Apache Server (httpd) on Centos 7
- 107648 Views Routing network traffic through a transparent SOCKS5 proxy using DD-WRT
- 76655 Views How to Unbrick TP-Link WiFi Router WR841ND using TFTP and Wireshark
- 75452 Views Android Reverse Engineering: Debugging Smali in Smalidea
- 62876 Views Clean Architecture : Part 2 – The Clean Architecture